
Questo rapporto descrive le cause tecniche dei recenti disservizi che hanno interessato Clash in Europa e Brasile.
Salve a tutti, sono Brian "Penrif" Bossé, del dipartimento tecnologico di League of Legends, e vorrei condividere con voi i dettagli dei problemi tecnici che hanno provocato i recenti disservizi in EUW, EUNE e Brasile verso la fine di febbraio. I dettagli sono prettamente tecnici, ma se siete curiosi di approfondire le cause di quei disservizi e di sapere cosa abbiamo fatto per risolverli imbarcatevi con me in un viaggio tra computer e grafici!
Creare la scena
Il primo sintomo che è stato riscontrato dal nostro vigile Centro di operazioni di rete è stata la drastica diminuzione delle partite avviate di LoL.
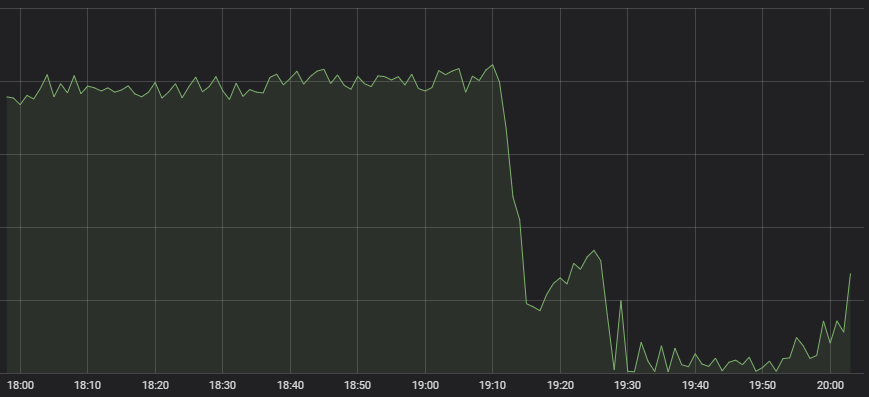
Comportamento atipico
Ci sono molti sistemi che contribuiscono a far funzionare la creazione di una partita, dal matchmaking alla distribuzione dei carichi sui server di gioco, e non è semplice intuire dove sia il guasto partendo da un sintomo come questo. Quando, per determinare il problema, ci siamo rivolti agli esperti di ciascuno dei sistemi coinvolti, hanno tutti indicato che lo stato dei loro rispettivi sistemi sembrava essere a posto, ma che la quantità di traffico ricevuta era molto bassa. Un sistema di matchmaking con poche persone che richiedono di giocare non ha molto lavoro da svolgere.
Quindi, tutto indicava che ci trovavamo di fronte a un problema sistemico nella ricezione del traffico dei giocatori nel nostro backend. I parametri ci indicavano dei problemi significativi in quel dipartimento:
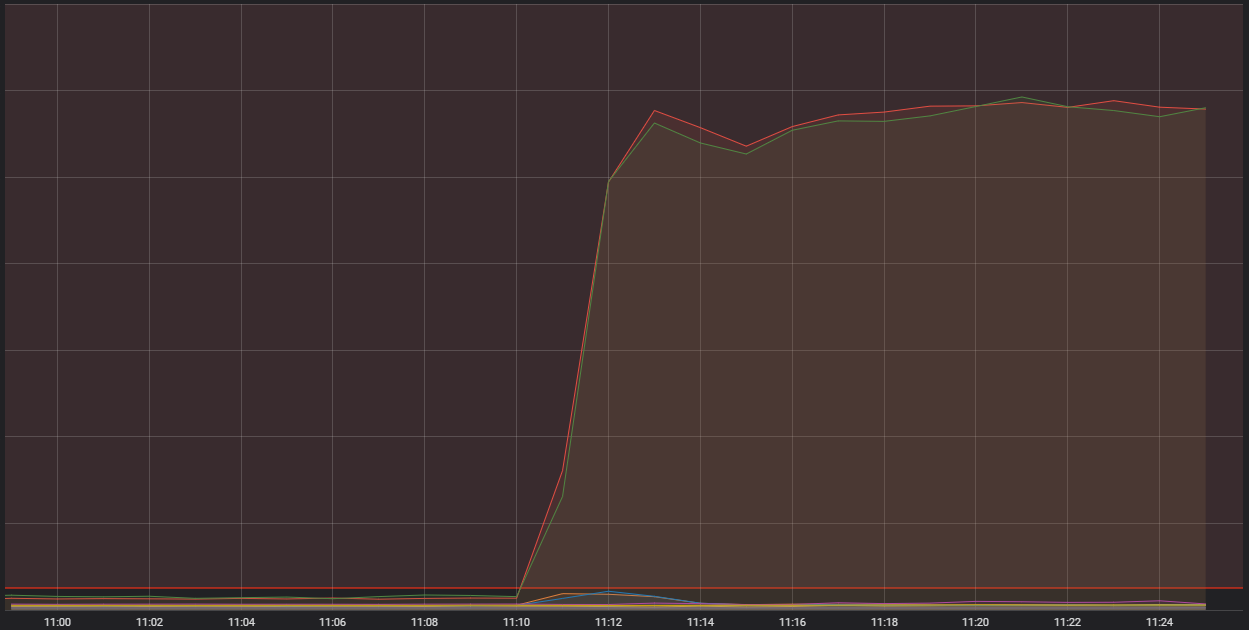
La linea orizzontale rossa nella parte bassa del grafico è la soglia di allarme
Ciò che abbiamo di fronte qui è il numero di connessioni in entrata di uno dei nostri container host generici. Si tratta di computer singoli molto potenti su cui girano alcune applicazioni più piccole (in gergo container) che costituiscono il sistema generale che fa funzionare LoL. Due di questi computer stavano ricevendo molte più connessioni del normale. Per capirne il motivo, dobbiamo parlare di un tipo particolare di container che esegue funzioni "edge".
Le funzioni edge
I processi edge si occupano di ricevere il traffico dalla rete, filtrarlo e reindirizzarlo nei servizi di backend appropriati. In pratica, prendono il mucchio di immondizia che costituisce Internet e lo trasformano in flussi di byte puliti e lineari che tutti possono elaborare comodamente. Come potete immaginare, i processi edge gestiscono una grande quantità di traffico, ma in realtà è raro che si trovino di fronte al tipo di picco che abbiamo visto durante questi eventi. Ci sono stati tre fattori che si sono allineati per creare questa situazione: li affronteremo in tre sezioni separate e poi li metteremo insieme.
E così ha inizio
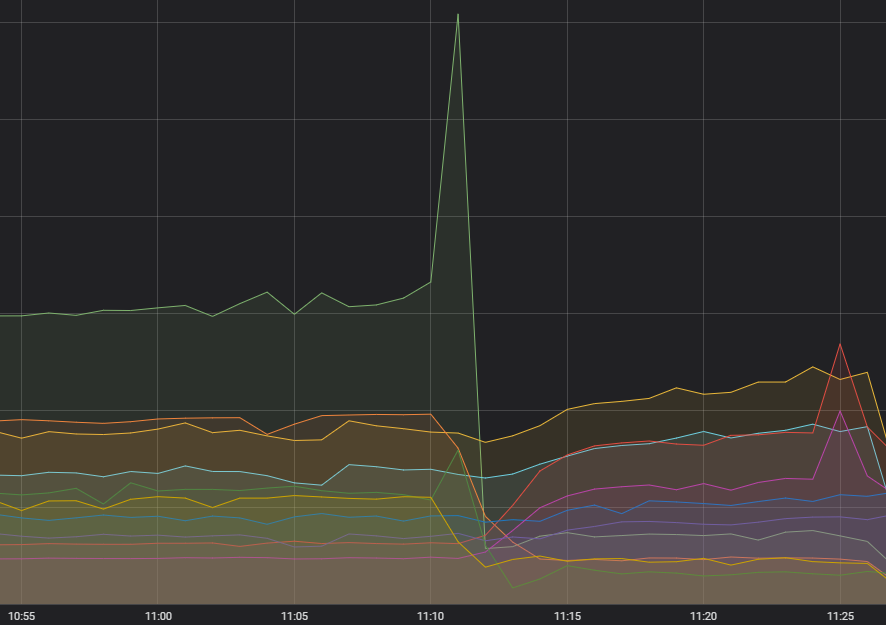
Per prima cosa, la scintilla che ha appiccato l'incendio: una quantità eccessiva di richieste a un solo servizio. Per alcuni mesi abbiamo notato un aumento della volatilità della frequenza delle chiamate dirette verso quel servizio, ma la cosa non sembrava avere alcun effetto e tutti i sistemi a monte la stavano gestendo senza problemi. Diagnosticare un problema che non causava alcun danno non costituiva una priorità degna di sforzi attivi, ma eravamo consapevoli della situazione. Adesso lo abbiamo diagnosticato: a causa di un errore nel modo in cui le richieste venivano effettuate, in alcuni casi queste fallivano costantemente e venivano continuamente ripetute.
Si è aperta una falla nei container
Avevamo un problema noto di interazione tra il nostro sistema di container e la versione del sistema operativo in uso. Ciò comportava una perdita di memoria all'interno del sistema operativo che, aumentando progressivamente nel tempo, poteva causare l'arresto di funzioni critiche del sistema stesso. Prima di questo evento non si era mai verificata questa eventualità, ma avevamo ugualmente già eseguito aggiornamenti su circa il 60% dei container della Riot. Purtroppo, l'aggiornamento di quelli europei e dell'America latina era ancora in corso.
La fortuna conta
E per finire, siamo stati sfortunati. Utilizziamo un software per riunire i container in gruppi che possano entrare in un singolo computer. Questo software è programmato con delle limitazioni che tengono questi servizi edge di rete separati tra loro all'interno dei gruppi di container della stessa regione. Tuttavia, non era possibile controllare se servizi edge di regioni diverse finissero sullo stesso computer: così, servizi edge della regione EUW potevano finire accanto a quelli di EUNE. Questo moltiplicarsi dei carichi su una singola macchina è stato il fattore che ha trasformato i due precedenti problemi in un incidente di grosse proporzioni.
In tutti i disservizi, i container edge di almeno tre regioni erano finiti su un singolo computer. La scintilla del traffico creato dalle richieste non valide, amplificata dalla presenza del traffico di più regioni su un unico computer, e la perdita di memoria del sistema operativo che ha messo la macchina in arresto, hanno causato un deterioramento dell'integrità dei server per le regioni colpite e dei notevoli disservizi.
Impatto e risoluzione
Generalmente, per risolvere questo genere di problemi e isolarne le cause servono degli sforzi cospicui. Quando abbiamo dovuto decidere se proseguire con Clash su un gruppo di macchine potenzialmente instabili, ci è venuto il sospetto che il problema dei container fosse un elemento chiave in questa situazione, ma non avevamo ancora capito del tutto a cosa fosse dovuto il traffico. Anche se il problema non era stato affatto causato da Clash, abbiamo deciso di ritardarlo di una settimana per essere sicuri di proteggere l'esperienza degli utenti. Mi scuso davvero per i disagi causati da questi eventi e voglio assicurarvi che abbiamo pronte delle soluzioni per ognuno degli aspetti che hanno avuto un ruolo in questa situazione.

Il codice che provocava le richieste non valide è stato corretto e, nel caso ci fossero problemi simili in futuro, abbiamo modificato il funzionamento del meccanismo con cui le richieste fallite vengono ripetute per evitare che questo causi grandi picchi. L'aggiornamento del software dei container è stato completato sui server di tutte le regioni. Abbiamo in programma di spostare i servizi edge su un sistema che riesca efficientemente a distribuirli tra una regione e l'altra. Mentre aspettiamo che questi piani entrino in atto, abbiamo allestito dei sistemi di allarme che fanno urlare il telefono degli addetti ai lavori finché il carico non viene redistribuito manualmente.
Siamo convinti che, ora che ci siamo lasciati alle spalle tutti questi problemi diversi, questa particolare situazione non si verificherà più. Detto questo, il gioco e i sistemi che lo supportano sono in continua evoluzione e situazioni come questa sono sempre una possibilità. Tuttavia, quando si verificano, ci impegniamo sempre a fondo per risolverle il prima possibile. Grazie per essere arrivati fin qui! Se questo tipo di contenuti accende la vostra curiosità, potete trovare altri articoli tecnici di approfondimento su LoL nel nostro TechBlog. In ogni caso, ci vediamo nella Landa.